How to use PostgreSQL like a message queue
PostgreSQL is an advanced open-source relational database. It is also very adaptable. It scales from very small use cases, to the largest enterprise operations. PostgreSQL also has several advanced features which go way beyond the normal relational database operations.
Developers have discovered you can use PostgreSQL as a document database, with performance that rivals dedicated solutions like MongoDB. You can use it as a key value store as an alternative to Redis.
Today I’m going to show you how you can use PostgreSQL like an asynchronous message queue, as an alternative to dedicated solutions like RabbitMQ. I’ve created a full featured implementation called pg_mq. Below I’ll show you the basic building blocks of what makes it work. Let’s dive in.
Wait, but why?
You might be wondering why I’d want to use a RDBMS as a message queue when there are dedicated solutions out there. The primary reason is because I wanted to see if I can! This was a learning exercise for me and I came out the other end with a lot of knowledge gained about Postgres.
Will it work for me?
You might find that this is useful for your project. Perhaps you work for a company who is heavily invested in PostgreSQL. You have DBAs that are experts at managing PostgreSQL installations. You might not have anyone who is an expert at deploying RabbitMQ or Kafka installations (which are notoriously tricky to manage.)
Perhaps you have PostgreSQL deployments in Amazon’s RDS, however you don’t want to increase vendor lock-in by using SQS.
Or maybe you want to implement an actor model or an event-driven architecture and need a message passing mechanism.
Or perhaps the most likely scenario is you have a very simple use case and you don’t want to bring an entire new solution online just for message queuing!
Naive approach
A naive message queue implementation might have consumers using polling to check for new messages. They might repeatedly run a SELECT on a table of messages every few seconds but often come back empty handed. This might work for simple use cases, but it’s not very efficient. It’s also difficult to ensure mutual exclusion and will cause race conditions unless implemented properly. Luckily PostgreSQL has a feature that allows us to switch from this “pull” architecture into a “push” architecture.
NOTIFY (and LISTEN)
The first feature we’ll talk about is NOTIFY. From the PostgreSQL docs:
NOTIFY provides a simple interprocess communication mechanism for a collection of processes accessing the same PostgreSQL database. A payload string can be sent along with the notification, and higher-level mechanisms for passing structured data can be built by using tables in the database to pass additional data from notifier to listener(s).
To start things off, one or more connections may listen to a channel specified by a static channel name.
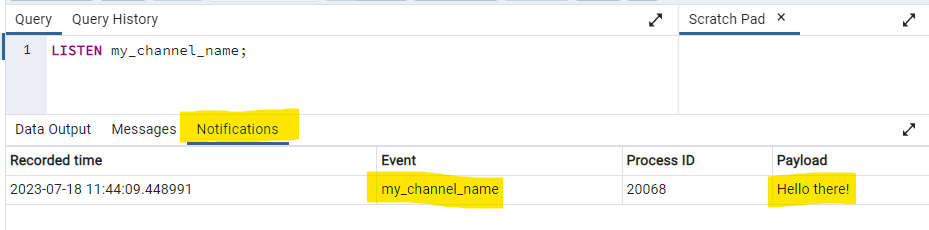
LISTEN my_channel_name;
Those connections are now subscribed to receive notification events from any other connection. The notifications are visible if you’re using pgAdmin to connect to your database. Additionally, PostgreSQL drivers for general purpose programming languages can receive these notification events. You can specify a function to execute when a message is received to do something interesting.
Meanwhile, in another connection we can to send a message.
NOTIFY my_channel_name, 'Hello there!'
All connections that called LISTEN my_channel_name; will now receive a message Hello there!.
Using these rudimentary LISTEN and NOTIFY operations, we can now define two types of actors in a message queue: a consumer and a producer. Consumers will use LISTEN to wait for new messages. Producers will call NOTIFY to send new messages.
This is the secret of how we will make our messages asynchronous. It escapes from the transactional constraints of normal database operations. By itself, LISTEN and NOTIFY is almost enough to make a message queue, however it delivers a copy of the same message to all consumers listening on a channel. This might be fine for publish/subscribe semantics, however we’ll need more if we want to make a work queue.
Implementing a work queue
Let’s start creating our schema to implement a work queue.
CREATE TABLE channel (
channel_name text PRIMARY KEY,
message_id int
);
CREATE TABLE message (
message_id serial PRIMARY KEY,
body json NOT NULL,
delivered boolean NOT NULL DEFAULT false
);
We have two tables channel and message. The channel table will store channel names to send messages to. Each row represents a listening consumer connection waiting for messages. The message_id is the message the consumer currently holds. When a new consumer connection joins it will insert into this table, then listen for messages.
INSERT INTO channel(channel_name) VALUES ('consumer_1');
LISTEN consumer_1;
The message table represents a queue of messages published to the system. A producer would insert into this table.
INSERT INTO message (body) VALUES
('{"hello":"world"}'),
('{"hello":"world 2"}'),
('{"hello":"world 3"}');
But the messages won’t do anything by themselves. Let’s add a trigger.
CREATE FUNCTION deliver_message() RETURNS TRIGGER AS $$
DECLARE
selected_channel_name text;
BEGIN
-- Find a channel that is not already holding a message.
-- Set the message ID to the NEW message ID.
UPDATE channel
SET message_id = NEW.message_id
WHERE channel_name = (
SELECT channel_name
FROM channel
WHERE message_id IS NULL
FOR UPDATE SKIP LOCKED
LIMIT 1
) RETURNING channel_name INTO selected_channel_name;
IF selected_channel_name IS NULL THEN
-- No channel was found, time to bail
RETURN NEW;
END IF;
-- Send a NOTIFY message to the channel with the JSON body of the message.
PERFORM pg_notify(selected_channel_name, row_to_json(NEW)::text);
-- Mark the message as delivered.
NEW.delivered = true;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER deliver_message_before_insert
BEFORE INSERT ON message
FOR EACH ROW EXECUTE PROCEDURE deliver_message();
The trigger takes over before INSERT. It checks for an unbusy channel with a null message_id, and sets the message_id. Lastly it calls the pg_notify function (which is equivalent to NOTIFY) and returns. The consumer that originally called LISTEN now receives a message!
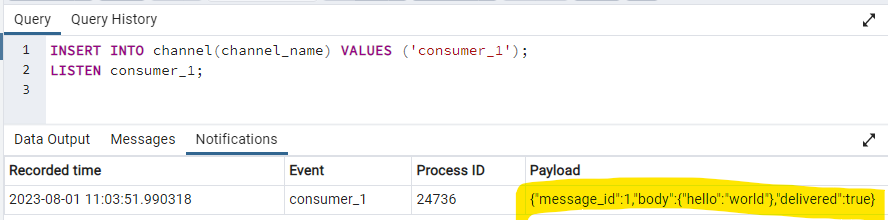
And we see that message #1 is delivered.
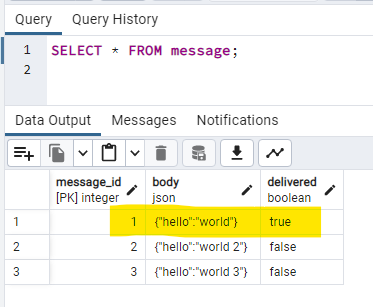
This works fine for one producer and one consumer. But what if there were many producers and many consumers? We have a race condition when picking the next channel to send the message to. If two producers published a message simultaneously, they might select the same channel to send the message to, or worse cause a deadlock when trying to lock the same row to update.
We can avoid a race condition by implementing mutual exclusion. Notice there are two special clauses FOR UPDATE and SKIP LOCKED. These two clauses combined give us mutually exclusive access to the channel table, which we’ll discuss next.
SELECT … FOR UPDATE SKIP LOCKED
PostgreSQL has another advanced feature that lets us implement a mutual exclusion mechanism. Adding the FOR UPDATE clause in SELECT statements will lock any rows returned by the SELECT until the end of the statement.
Additionally, the SKIP LOCKED clause can be specified. This will skip over any rows that aren’t currently locked instead of waiting for them to be unlocked.
When used in combination (FOR UPDATE SKIP LOCKED) we can choose an available channel, and update it in the same atomic operation, preventing a race condition. Other simultaneous connections cannot select the same row because it is locked, nor will they be blocked waiting for locked rows, and will choose another available row.
SELECT channel_name
FROM channel
WHERE message_id IS NULL
FOR UPDATE SKIP LOCKED
LIMIT 1
Acknowledging messages
Now we need to create a way to keep the messages flowing. Message #1 was delivered, but messages #2 and #3 are still waiting in the queue. Consumers must “consume” messages and move on to the next message in the queue. Let’s create a procedure for consumers to call when they’re done processing the message.
The procedure will delete the currently consumed message. Then to take the next message in the queue, we can use an UPDATE statement with the same FOR UPDATE SKIP LOCKED trick.
CREATE PROCEDURE ack (message_id bigint, channel_name text) LANGUAGE plpgsql AS $$
DECLARE
selected_message_id int;
BEGIN
-- Throw away the message, since it's done processing.
DELETE FROM message m WHERE m.message_id = ack.message_id;
-- Find the next message that isn't delivered.
-- Set it to delivered to take it from the queue.
UPDATE message m SET delivered = true
WHERE m.message_id = (
SELECT mm.message_id
FROM message mm
WHERE mm.delivered = false
FOR UPDATE SKIP LOCKED
LIMIT 1
) RETURNING m.message_id INTO selected_message_id;
-- Set the message on this channel so it's marked as busy.
UPDATE channel c SET message_id = selected_message_id
WHERE c.channel_name = ack.channel_name;
IF selected_message_id IS NULL THEN
-- No message was waiting, time to bail.
RETURN;
END IF;
-- Send a NOTIFY message to this channel with the JSON body of the message.
PERFORM pg_notify(
ack.channel_name,
(SELECT row_to_json(m.*) FROM message m WHERE m.message_id = selected_message_id)::text);
END;
$$;
A consumer can then call this procedure to acknowledge a message.
CALL ack(message_id=>1, channel_name=>'consumer_1');
Message #2 will now be delivered to that consumer via NOTIFY and the cycle continues.
With that, we’re done! We’ve implemented a very rudimentary message queue with producers and consumers.
General purpose programming languages
To do something interesting when receiving messages, we need to connect with a general purpose programming language. Here’s an example using C# and npgsql.
var dataSource = NpgsqlDataSource.Create(connectionString);
var conn = dataSource.CreateConnection();
conn.Open();
conn.Notification += (o, e) => Console.WriteLine("Received notification");
using var listen = new NpgsqlCommand(
"INSERT INTO channel(channel_name) VALUES ('consumer_1'); LISTEN consumer_1;",
conn);
listen.ExecuteNonQuery();
while (true)
{
conn.Wait(TimeSpan.FromSeconds(10)); // Thread will block here
}
The npgsql connection has an event sink named Notification where events are fired when the connection receives a notification from PostgreSQL. If we attach a lambda, then we can do work when the notification is received.
conn.Notification += (o, e) =>
{
var message = JsonSerializer.Deserialize<Message>(e.Payload);
Console.WriteLine($"Message received: {message.MessageId}");
// This is where you would normally do work in a work queue.
// Instead we'll just sleep to simulate work.
Thread.Sleep(1000);
Console.WriteLine($"Acknowledging message: {message.MessageId}");
Ack(message.MessageId);
};
public class Message
{
[JsonPropertyName("message_id")]
public int MessageId { get; set; }
[JsonPropertyName("body")]
public JsonNode Body { get; set; }
}
Finally to acknowledge the message, we call the procedure ack.
void Ack(int message_id)
{
using var cmd = dataSource.CreateCommand();
cmd.CommandText = "ack";
cmd.CommandType = CommandType.StoredProcedure;
cmd.Parameters.Add(new NpgsqlParameter { Value = message_id });
cmd.Parameters.Add(new NpgsqlParameter { Value = "consumer_1" });
cmd.ExecuteNonQuery();
}
Running this simple console app, we see that it works through the messages one at a time.
$ dotnet run
Message received: 1
Acknowledging message: 1
Message received: 2
Acknowledging message: 2
Message received: 3
Acknowledging message: 3
pg_mq
The message queue we’ve created above is a very simple proof of concept that is lacking many features you might want to have in a generalized message queue solution.
Luckily, I’ve created a more advanced implementation. I call it pg_mq. I encourage you to try it out.
Conclusion
Using PostgreSQL in this unconventional way shows its power and adaptability. Hopefully you learned something from the examples. Go and try it for yourself!
Recommended reading
- Mastering PostgreSQL 15 by Hans-Jurgen Schonig
- Learning SQL by Alan Beaulieu